
无题
Java面经
面经一
公司地点:珠海
公司业务:消防安全预警平台 + 物联网
面试次数:仅一轮
JD薪资:8K-13K
面试岗位:Java后端开发(去到突然变成面全栈。。。)
- String、StringBuilder 和 StringBuffer 的区别
String 是只读字符串,也就意味着 String 引用的字符串内容是不能被改变的。
StringBuffer/StringBuilder 表示的字符串对象可以直接进行修改,buffer是线程安全的,builder的效率更高
- MySQL数据库语句的查询顺序
1 | from -> on -> join -> where -> group by -> having -> select distinct -> order by -> limit |
- vue.js的生命周期
(没有前端基础,参考一下chatGPT的)
- beforeCreate:Vue实例刚被创建,数据观测(data observer)和事件配置都未开始。此时,模板和组件并未渲染,data和methods都不能访问。
- created:Vue实例已经完成了数据观测(data observer),属性和方法的运算,事件回调也已经被设置。但是模板和组件还未渲染。此时,可以访问data和methods,但不能保证能访问到$el。
- beforeMount:在挂载之前调用。此时,Vue实例的$el和data都已初始化,但是模板和组件还未渲染。在这个阶段,可以修改$el中的DOM结构。
- mounted:Vue实例已经完成了模板和组件的渲染,并将其挂载到DOM上。此时,可以访问到$el中的DOM结构。这个阶段也是常用的异步数据获取的阶段。
- beforeUpdate:在数据更新之前调用。此时,Vue实例的数据已更新,但是DOM还未更新。在这个阶段,可以对更新前的数据进行一些处理。
- updated:在数据更新后调用。Vue实例的数据和DOM都已更新。在这个阶段,可以对更新后的数据和DOM进行操作。
- beforeDestroy:在实例销毁之前调用。在这个阶段,Vue实例仍然完全可用,可以访问所有数据和方法。
- destroyed:在实例销毁之后调用。在这个阶段,Vue实例及其所有的指令和事件监听器都已经被销毁,无法再访问其中的数据和方法。
如果一个网页页面上要加载大量图片,要怎么处理
- 压缩图片大小
- 延迟加载(懒加载)
- 使用CSS Sprite,将小图片组合成大图片
- CDN加速
- 缓存
MySQL的索引是基于什么实现的
B+树
哪些情况会出现索引不命中
- 没有使用索引列
- 使用索引错误
- 索引列数据分布不均
- 数据库表过度规范化
- 查询条件不适合索引
- 数据库表数据量过大
索引有哪些类型
- 普通索引:允许被索引的数据列包含重复的值
- 唯一索引:可以保证数据记录的唯一性
- 主键索引:是一种特殊的唯一索引,在一张表中只能定义一个主键索引,主键用于唯一标识一条记录,使用关键字primary key来创建
- 联合索引:索引可以覆盖多个数据列
- 全文索引:通过建立倒排索引,可以极大的提升检索效率,解决判断字段是否包含的问题,是目前搜索引擎使用的一种关键技术
聚簇索引和非聚簇索引的区别
跟数据绑定在一起的就是聚簇索引
对MySQL的集群有了解吗
MySQL主从复制是怎么实现的,主从复制之间的延迟有计算过吗
- 监控工具
- sql语句:在主库和从库执行以下代码,相减就是延迟时间
1 | select UNIX_TIMESTAMP(); |
- 有用过数据库连接池吗
连接池通常包含以下组件:
- 连接池管理器:用于管理连接池中的数据库连接,包括创建连接、回收连接、销毁连接等操作。
- 连接池配置信息:包括数据库的连接URL、用户名、密码等信息,以及连接池的配置参数,如最大连接数、最小连接数、连接超时时间等。
- 数据库连接:连接池中的数据库连接,应用程序可以从连接池中获取连接,并在使用完成后将连接归还给连接池。
MySQL数据库连接池的常见实现包括:
- C3P0:C3P0是一个开源的JDBC连接池,支持连接池自动回收、断线重连、连接泄漏检测等功能。
- DBCP:DBCP是Apache软件基金会的一个开源JDBC连接池,支持连接池自动回收、连接泄漏检测等功能。
- Druid:Druid是阿里巴巴开源的一个JDBC连接池,支持连接池自动回收、断线重连、连接泄漏检测、SQL防注入等功能,还提供了一些监控和性能分析功能
- 了解MySQL8吗,相比5版本新增什么功能
(参考chatGPT)
- Window Functions:窗口函数是一种在一组行上执行计算的函数,它可以将查询结果分区并按指定的排序规则排序,从而使得在一组行上进行聚合和排序更加方便。
- Common Table Expressions (CTE):通用表达式是一种创建临时表并在查询中引用的方法,它可以提高查询的可读性和复用性。
- JSON支持:MySQL 8增加了对JSON数据类型的支持,并且提供了许多内置函数来处理JSON数据,包括JSON_EXTRACT、JSON_OBJECT、JSON_ARRAY等。
- Invisible Indexes:隐形索引是一种在不影响现有查询计划的情况下隐藏索引的方法,它可以减少索引对查询性能的影响,同时也提高了数据库的维护性。
- CTE优化:MySQL 8对CTE的执行进行了优化,包括在CTE上执行查询优化、避免在CTE中进行排序和分组、将CTE中的过滤器下推到查询中等。
- Group Replication:MySQL 8引入了一种新的集群解决方案,称为组复制,它是一种基于Paxos协议的多主复制技术,可以提供高可用性和数据一致性。
- Atomic DDL statements:MySQL 8支持原子DDL语句,可以在单个事务中执行DDL语句,从而保证DDL语句的原子性和一致性。
- Unicode 9.0支持:MySQL 8支持Unicode 9.0字符集,可以存储更多的字符和符号。
- 增强的安全性:MySQL 8引入了一些新的安全功能,包括密码策略、默认启用SSL连接、新的加密算法等。
Nginx的负载均衡方法,怎么部署
Nginx提供了多种负载均衡方法,包括:
- 轮询(Round Robin):默认情况下,Nginx会使用轮询算法将请求依次分配给不同的后端服务器。
- IP哈希(IP Hash):Nginx可以根据客户端IP地址将请求路由到特定的服务器上。这种方式通常用于需要保持会话的应用程序。
- 最少连接(Least Connections):Nginx可以将请求发送到连接数最少的服务器上。这种方式通常用于处理连接数较多的场景。
- URL哈希(URL Hash):Nginx可以根据请求URL将请求路由到特定的服务器上。这种方式通常用于静态文件服务。
Nginx的负载均衡配置通常包括以下几个步骤:
- 在Nginx配置文件中定义后端服务器列表。
- 配置负载均衡方法,可以选择默认的轮询算法或其他算法。
- 配置代理服务器和反向代理服务器,以将请求转发到后端服务器。
你一般用redis缓存什么数据
谈一谈Http的状态码
3xx 类状态码表示客户端请求的资源发生了变动,需要客户端用新的 URL 重新发送请求获取资源,也就是重定向。
- 「301 Moved Permanently」表示永久重定向,说明请求的资源已经不存在了,需改用新的 URL 再次访问。
- 「302 Found」表示临时重定向,说明请求的资源还在,但暂时需要用另一个 URL 来访问。
301 和 302 都会在响应头里使用字段 Location,指明后续要跳转的 URL,浏览器会自动重定向新的 URL。
- 「304 Not Modified」不具有跳转的含义,表示资源未修改,重定向已存在的缓冲文件,也称缓存重定向,也就是告诉客户端可以继续使用缓存资源,用于缓存控制。
4xx 类状态码表示客户端发送的报文有误,服务器无法处理,也就是错误码的含义。
- 「400 Bad Request」表示客户端请求的报文有错误,但只是个笼统的错误。
- 「403 Forbidden」表示服务器禁止访问资源,并不是客户端的请求出错。
- 「404 Not Found」表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端。
5xx 类状态码表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码。
- 「500 Internal Server Error」与 400 类型,是个笼统通用的错误码,服务器发生了什么错误,我们并不知道。
- 「501 Not Implemented」表示客户端请求的功能还不支持,类似“即将开业,敬请期待”的意思。
- 「502 Bad Gateway」通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。
- 「503 Service Unavailable」表示服务器当前很忙,暂时无法响应客户端,类似“网络服务正忙,请稍后重试”的意思
如何使用mybatis导入一个集合并循环操作
- 在Mapper.xml文件中编写SQL语句,查询需要导入的数据,并使用resultMap将结果映射到实体类中。
- 在DAO层中定义方法,调用MyBatis的selectList方法执行查询操作,并返回查询结果。
- 在Service层中获取DAO层返回的查询结果,使用循环语句遍历集合中的每个元素。
- 在循环语句中,调用DAO层定义的方法进行数据的新增、修改或删除操作。
如何在Java层获取数据库的自增id
- 使用JDBC的 getGeneratedKeys方法
- 使用Mybatis的 useGeneratedKeys 和 keyProperty属性获取
数据库存在的意义是什么,为什么不用文件存储
数据库的优点:
- 数据库可以对数据进行结构化存储和管理,保证数据的一致性和可靠性,同时方便对数据进行查询、修改和删除
- 实现了用户多并发访问,保证了数据的并发安全性,避免了数据的冲突和损坏
- 数据库提供了数据备份和恢复的功能,保证了数据的安全性
相比于文件存储,数据库的优势在于数据管理的可靠性和高效性方面。同时数据库的优点是文件存储自身无法实现的,所以使用数据库是更加合适的选择。
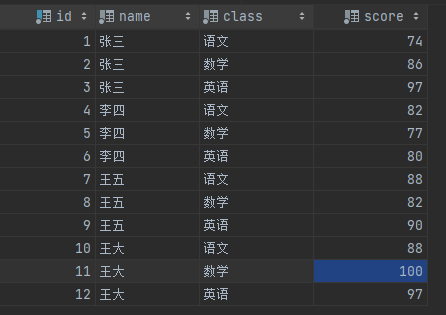
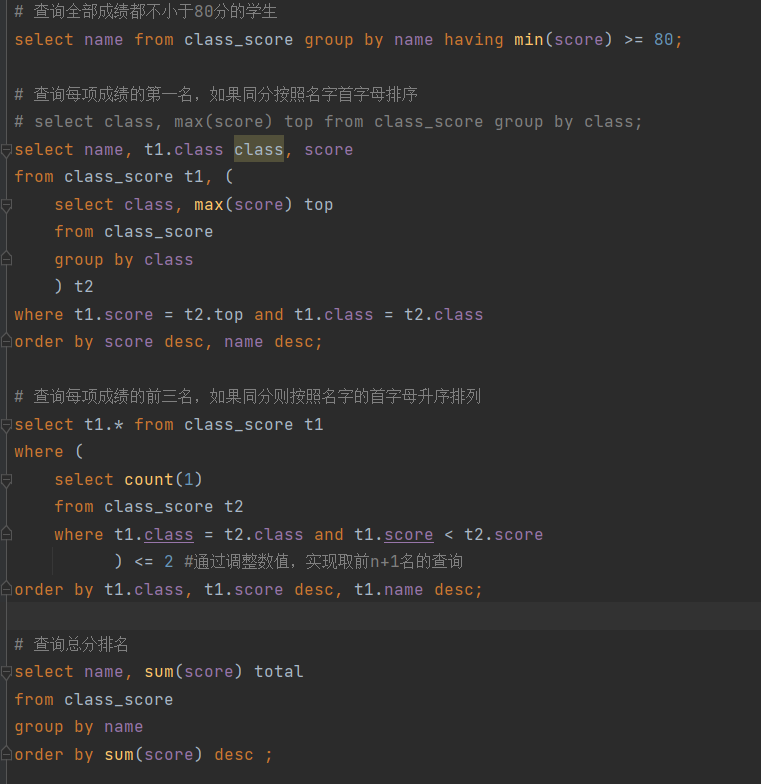
- 算法题:
根据以下例子,写一个方法(可伪代码)
- 输入a,输出a
- 输入aa,输出a2
- 输入aaabbbccc,输出a3b3c3
手撕思路:双指针遍历
- MySQL手撕
面经二
Java的三大特性
String 、StringBuilder 和 StringBuffer 的区别
forward 和 redirect 的区别
值传递和引用传递的区别
谈谈你对IOC的理解
创建线程有几种方式
谈谈对多线程的锁的理解
什么是XSS攻击
什么是SQL注入攻击
什么是CSRF攻击
final、finally、finalize 之间的区别
集合类的基本接口有哪些
数据库集群怎么搭建
简单说一下二分查找的流程
你还会什么排序算法(满脑子都是冒泡o(╥﹏╥)o)
二分查找和冒泡排序有什么区别
什么是ORM
问项目–学成在线
说一下你印象最深的模块(媒资)
断点续传怎么实现
视频转码怎么实现
对SaaS平台的了解
反问:
- 贵公司招聘这个岗位是处理什么业务的
- 如果我有幸加入贵公司,鉴于今天的面试情况,您觉得我的能力还有哪些方面可以提升呢
面经三


- Spring MVC是一个Web框架,用于构建Web应用程序。它提供了一组基于注解的API和配置选项,可以帮助开发者构建MVC架构的Web应用程序。
- Spring Boot是一个快速构建Web应用程序的框架。它是一个基于Spring框架的快速开发框架,可以自动配置Spring和第三方库,并提供了大量的起步依赖项,使得开发者可以快速搭建一个基于Spring的Web应用程序,而无需手动配置太多的参数。
因此,Spring MVC和Spring Boot的主要区别在于:
- 功能不同:Spring MVC主要用于构建Web应用程序,而Spring Boot则是一个快速构建Web应用程序的框架。
- 配置方式不同:Spring MVC需要手动配置参数和依赖项,而Spring Boot则自动配置Spring和第三方库,并提供了大量的起步依赖项。
- 开发效率不同:使用Spring Boot可以提高开发效率,因为它可以自动配置和集成第三方库,而Spring MVC需要手动配置很多参数和依赖项。
综上所述,如果你需要构建一个Web应用程序,可以选择使用Spring MVC,如果你需要快速构建Web应用程序并且对配置要求较低,可以选择使用Spring Boot。
PostMapping
接收键值对形式的请求,一般使用@RequestParams
接收JSON形式的请求,一般使用@RequestBody
MultipartFile:用于接收单个文件上传的参数
List
:用于接收多个文件上传的参数 使用MultipartFile接收文件参数时,需要在前端表单中添加enctype=”multipart/form-data”属性,并且需要使用POST请求方式提交表单
示例代码:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public String handleFileUpload( MultipartFile file) {
// 获取文件名
String fileName = file.getOriginalFilename();
// 获取文件后缀名
String suffixName = fileName.substring(fileName.lastIndexOf("."));
// 生成新的文件名
String newFileName = UUID.randomUUID().toString() + suffixName;
// 设置文件存储路径
String filePath = "D:/uploads/";
File dest = new File(filePath + newFileName);
try {
// 将上传的文件保存到指定目录下
file.transferTo(dest);
// 返回上传成功信息
return "upload success";
} catch (IOException e) {
e.printStackTrace();
}
// 返回上传失败信息
return "upload failed";
}
- 在接口中添加这个方法来实现添加用户的功能:
2
3
void addUser(User user);
}
- 在Mapper配置文件中定义该接口方法对应的SQL语句
2
3
insert into user(name, age, email) values(#{name}, #{age}, #{email})
</insert>
- 在代码中调用该接口方法即可完成用户添加操作
2
3
4
5
6
private UserMapper userMapper;
public void addUser(User user) {
userMapper.addUser(user);
}
Mybatis 实现一个接口,接口的参数形式有以下几种:
使用JavaBean类型作为参数
定义JavaBean类User
public class User { private Integer id; private String name; private Integer age; private String email; // getters and setters }
2
3
4
5
6
7
- 定义UserMapper接口
- ```java
public interface UserMapper {
void addUser(User user);
}在Mapper配置文件中定义SQL语句
```java
insert into user(name, age, email) values(#{name}, #{age}, #{email})
2
3
4
5
6
7
8
9
10
11
- 在代码中调用该接口方法
- ```java
@Autowired
private UserMapper userMapper;
public void addUser(User user) {
userMapper.addUser(user);
}
使用@Param注解指定参数名称
定义UserMapper接口
public interface UserMapper { void addUser(@Param("name") String name, @Param("age") Integer age, @Param("email") String email); }
2
3
4
5
6
7
- 在Mapper配置文件中定义SQL语句
- ```java
<insert id="addUser" parameterType="java.util.Map">
insert into user(name, age, email) values(#{name}, #{age}, #{email})
</insert>在代码中调用该接口方法
@Autowired private UserMapper userMapper; public void addUser(String name, Integer age, String email) { userMapper.addUser(name, age, email); }
2
3
4
5
6
7
8
9
3. 使用Map类型作为参数
- 定义UserMapper接口
- ```java
public interface UserMapper {
void addUser(Map<String, Object> params);
}在Mapper配置文件中定义SQL语句
```java
insert into user(name, age, email) values(#{name}, #{age}, #{email})
2
3
4
5
6
7
8
9
10
11
12
13
14
- 在代码中调用该接口方法
- ```java
@Autowired
private UserMapper userMapper;
public void addUser(String name, Integer age, String email) {
Map<String, Object> params = new HashMap<>();
params.put("name", name);
params.put("age", age);
params.put("email", email);
userMapper.addUser(params);
}
SELECT name FROM user ORDER BY num ASC;
SELECT name FROM user WHERE num >= (SELECT num FROM user ORDER BY num ASC LIMIT 19, 1) LIMIT 10;
该语句中的子查询
SELECT num FROM user ORDER BY num ASC LIMIT 19, 1表示从user表中按照num字段升序排序后,跳过前19行记录,然后取第20行的num值作为起始条件。接着使用主查询SELECT name FROM user WHERE num >= ... LIMIT 10,根据起始条件从第20行开始向下查找,取10条记录,并返回这些记录中的name字段
第一行的偏移量为0,所以limit的起始值为0
SELECT *
FROM user
LEFT JOIN info
ON user.num = info.num;
在已经搭建好的商品系统中添加秒杀功能,需要考虑以下几个方面:
- 数据库设计
为了支持秒杀功能,需要在数据库中添加一个秒杀商品表,该表至少应该包括以下字段:
- 商品 ID
- 秒杀开始时间
- 秒杀结束时间
- 秒杀价格
- 库存数量
同时,在商品表中,需要增加一个字段,用来标识商品是否支持秒杀。
- 秒杀接口设计
为了实现秒杀功能,需要设计一个秒杀接口,该接口需要满足以下要求:
- 接口需要验证用户是否已经登录。
- 接口需要判断商品是否已经开始秒杀,如果没有开始秒杀,需要返回秒杀未开始的错误信息。
- 接口需要判断商品是否已经结束秒杀,如果已经结束秒杀,需要返回秒杀已结束的错误信息。
- 接口需要判断商品是否有库存,如果库存不足,需要返回库存不足的错误信息。
- 接口需要使用事务保证秒杀的原子性,同时需要防止超卖现象的发生。
- 秒杀系统优化
为了保证秒杀系统的高并发性能,需要进行系统优化,包括但不限于以下方面:
- 使用缓存技术,减轻数据库压力。
- 使用分布式技术,将请求分散到多台服务器上处理,提高系统吞吐量。
- 使用消息队列技术,异步处理秒杀请求,提高系统的并发能力和稳定性。
- 使用负载均衡技术,将请求均衡分配到多台服务器上,提高系统的可用性和性能。
秒杀系统需要加锁来保证数据的一致性和并发安全。这里考虑使用分布式锁
在秒杀系统中,可以使用分布式锁来解决并发问题。例如,可以使用 Redis 的分布式锁来保证同一时刻只有一个用户可以执行秒杀操作。分布式锁的实现方式较为灵活,可以根据具体需求选择适合的实现方式。
将a.sh脚本的归属更改为B用户,可以使用 chown 命令:
sudo chown B a.sh
继承 Thread 类,重写 run 方法,并创建 Thread 实例后调用 start 方法启动线程
```java
public class MyThread extends Thread {
@Override
public void run() {
// 线程要执行的代码
}
}MyThread thread = new MyThread();
thread.start();
2
3
4
5
6
7
8
9
10
11
12
13
14
2. 实现 Runnable 接口,重写 run 方法,并通过 Thread 类的构造方法将 Runnable 实例传入创建 Thread 实例后调用 start 方法启动线程
- ```java
public class MyRunnable implements Runnable {
@Override
public void run() {
// 线程要执行的代码
}
}
MyRunnable runnable = new MyRunnable();
Thread thread = new Thread(runnable);
thread.start();使用 Callable 和 Future 接口创建带有返回值的线程,Callable 接口中的 call 方法返回线程执行的结果,可以通过 Future 接口获取
```java
public class MyCallable implements Callable{
@Override
public Integer call() throws Exception {
// 线程要执行的代码
return 1;
}
}MyCallable callable = new MyCallable();
ExecutorService executorService = Executors.newSingleThreadExecutor();
Futurefuture = executorService.submit(callable);
2
3
4
5
6
7
8
4. 使用线程池创建线程,避免频繁创建和销毁线程带来的性能损失和资源浪费
- ```java
ExecutorService executorService = Executors.newFixedThreadPool(10);
executorService.execute(() -> {
// 线程要执行的代码
});
多线程的操作逻辑一般写在
run()方法中,这个方法需要被子线程重写实现
实现
Runnable接口的方式
2
3
4
5
6
public void run() {
// 操作逻辑
}
}在创建线程时,将
MyRunnable对象作为参数传入Thread构造方法中
2
3
Thread thread = new Thread(myRunnable);
thread.start();继承
Thread类的方式
2
3
4
5
6
public void run() {
// 操作逻辑
}
}然后直接创建
MyThread对象并启动线程
2
myThread.start();
可以使用Apache POI库来读写Excel文件,使用JDBC来连接数据库并将数据导入数据库中
读取Excel文件并获取数据
使用POI库读取Excel文件中的数据,具体操作可参考官方文档或相关教程。读取完成后,可以将数据存储在一个Java对象中,例如
List<MyData>。连接数据库
使用JDBC来连接数据库。具体操作可参考JDBC相关教程,一般需要指定数据库的URL、用户名和密码等信息。
将数据插入数据库中
将读取到的Excel数据插入数据库中,可以使用JDBC提供的
PreparedStatement对象
2
3
4
5
6
7
PreparedStatement ps = conn.prepareStatement("INSERT INTO my_table (column1, column2) VALUES (?, ?)");
for (MyData data : dataList) {
ps.setString(1, data.getColumn1());
ps.setString(2, data.getColumn2());
ps.executeUpdate();
}完整的代码示例如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
List<MyData> dataList = new ArrayList<>();
Workbook workbook = WorkbookFactory.create(new File("path/to/excel/file"));
Sheet sheet = workbook.getSheetAt(0);
for (Row row : sheet) {
MyData data = new MyData();
data.setColumn1(row.getCell(0).getStringCellValue());
data.setColumn2(row.getCell(1).getStringCellValue());
dataList.add(data);
}
// 2. 连接数据库
String url = "jdbc:mysql://localhost/mydatabase";
String username = "root";
String password = "mypassword";
Connection conn = DriverManager.getConnection(url, username, password);
// 3. 将数据插入数据库中
PreparedStatement ps = conn.prepareStatement("INSERT INTO my_table (column1, column2) VALUES (?, ?)");
for (MyData data : dataList) {
ps.setString(1, data.getColumn1());
ps.setString(2, data.getColumn2());
ps.executeUpdate();
}
// 关闭资源
ps.close();
conn.close();
workbook.close();
- 读取一个本地文本文件,可以使用Java中的File和Scanner类来实现
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import java.io.FileNotFoundException;
import java.util.Scanner;
public class ReadTextFile {
public static void main(String[] args) {
// 指定要读取的文件路径
String filePath = "C:\\example.txt";
// 创建一个File对象
File file = new File(filePath);
try {
// 创建一个Scanner对象读取文件
Scanner scanner = new Scanner(file);
// 逐行读取文件内容
while (scanner.hasNextLine()) {
String line = scanner.nextLine();
System.out.println(line);
}
// 关闭Scanner对象
scanner.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
- 使用字符流可以使用Java中的
FileReader类来读取本地文本文件
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
public class ReadTextFile {
public static void main(String[] args) {
File file = new File("test.txt"); // 指定本地文件路径
try {
FileReader reader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(reader);
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
bufferedReader.close();
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
使用Java的文件输入流(FileInputStream)和字符输入流(InputStreamReader)来读取本地文件,然后通过标准输出流(System.out)将读取到的内容输出到控制台
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
public class FileReaderExample {
public static void main(String[] args) {
// 指定要读取的文件路径
String filePath = "C:\\example.txt";
File file = new File(filePath);
BufferedReader reader = null;
try {
// 创建文件输入流
FileInputStream fis = new FileInputStream(file);
// 创建字符输入流
InputStreamReader isr = new InputStreamReader(fis);
// 创建缓冲字符输入流
reader = new BufferedReader(isr);
String line;
// 逐行读取文件内容并输出到控制台
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (reader != null) {
reader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
常见的拦截器类型包括:
- 前置拦截器(Pre-Handler Interceptor):在请求到达Controller层之前,对请求进行拦截和处理,例如权限认证、参数校验等。
- 后置拦截器(Post-Handler Interceptor):在Controller层处理完请求并返回响应后,对响应进行拦截和处理,例如日志记录、异常处理等。
- 环绕拦截器(Around-Handler Interceptor):在请求到达Controller层之前和处理完请求并返回响应之后,对请求和响应进行拦截和处理,可以实现前置和后置拦截器的功能。
- 异常拦截器(Exception Interceptor):在Controller层抛出异常时,对异常进行拦截和处理,例如统一异常处理、异常日志记录等。
在 Spring Boot 中,可以通过实现
WebMvcConfigurer接口并重写addInterceptors方法来配置拦截器。具体步骤如下:
- 创建一个拦截器类,实现
HandlerInterceptor接口,重写需要的方法。- 创建一个配置类,实现
WebMvcConfigurer接口,重写addInterceptors方法。- 在
addInterceptors方法中,调用registry.addInterceptor方法,将拦截器注册到拦截器链中,并设置拦截器的拦截路径示例代码:
2
3
4
5
6
7
8
9
10
public class MyInterceptorConfig implements WebMvcConfigurer {
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new MyInterceptor())
.addPathPatterns("/**") // 设置拦截路径
.excludePathPatterns("/login"); // 设置排除拦截的路径
}
}